Neural Networks Learning Notes
All Screenshots below are from StatQuest.
Part1: Inside the Black Box
Backgrounds of Example
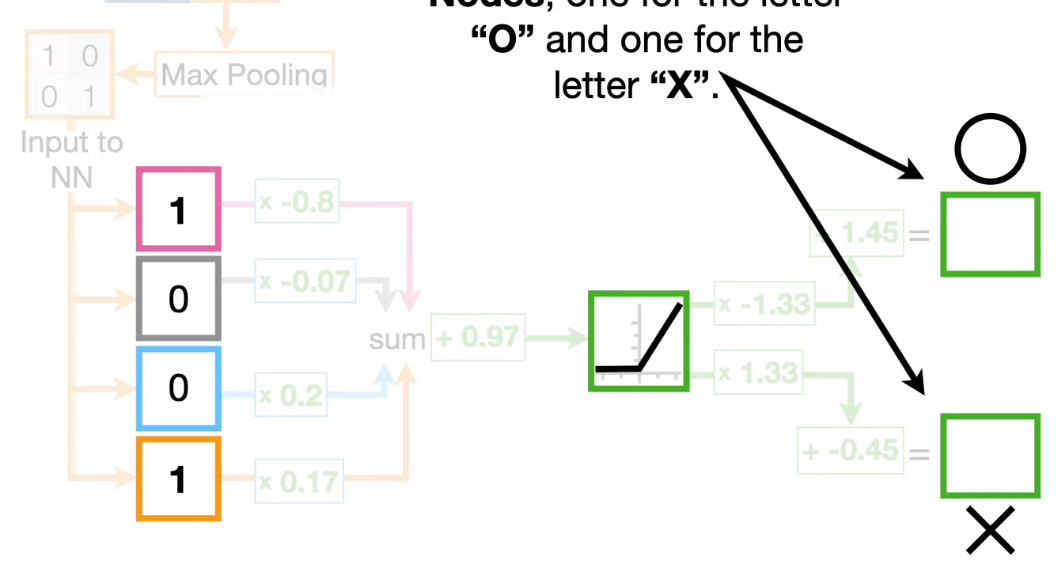
A neural_networks consist of nodes and connections between the nodes.
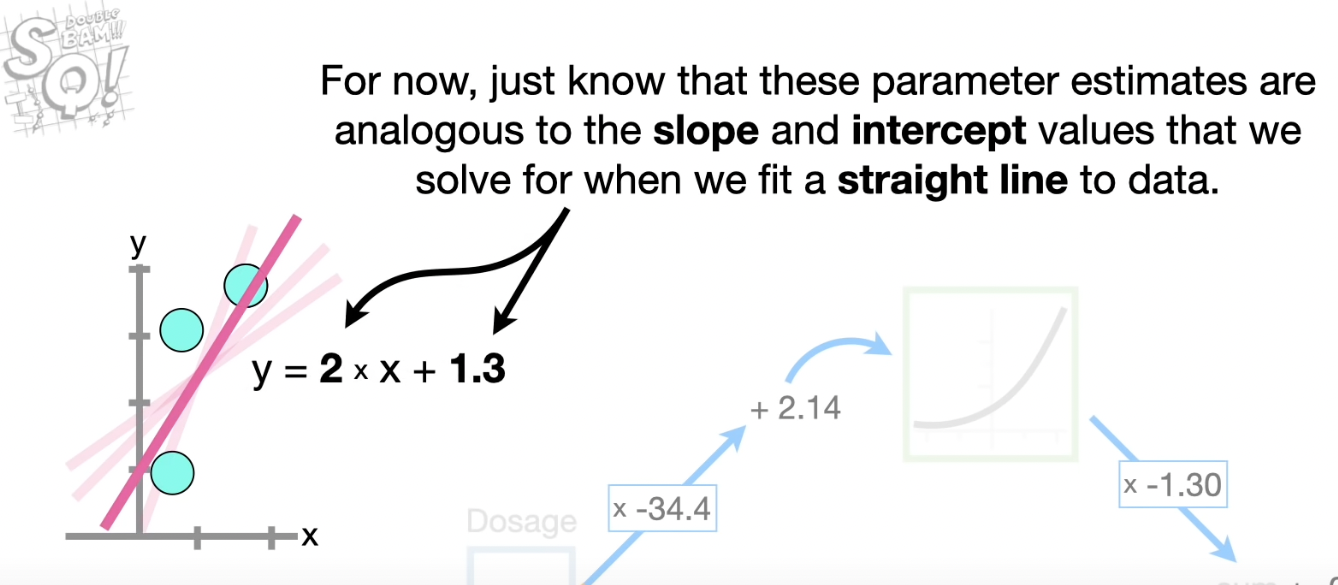
The network starts out with unknown parameter values that are estimated using Back Propagation
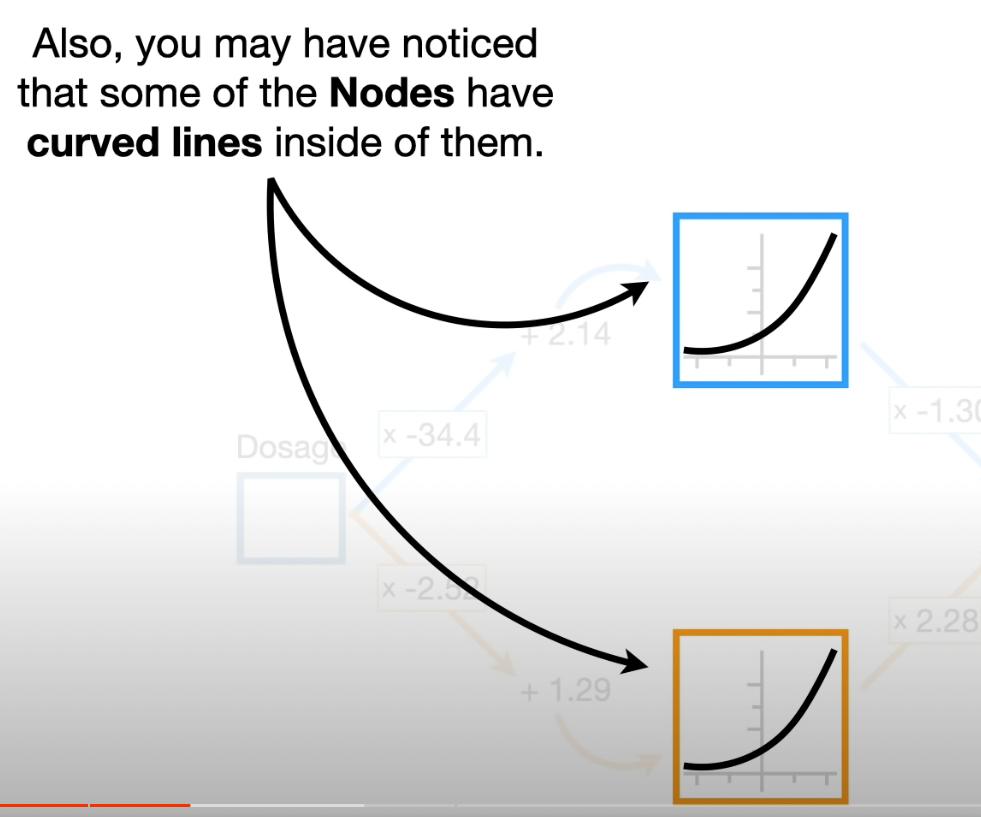
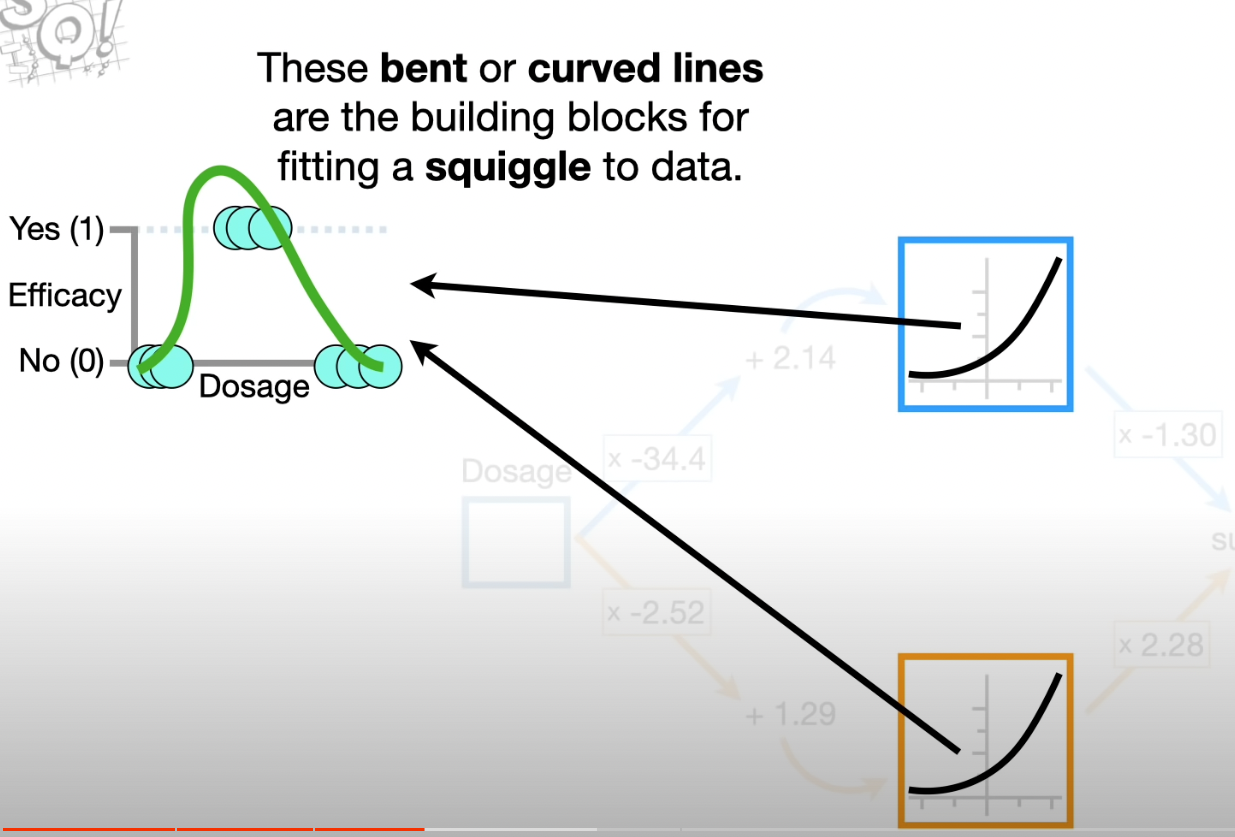
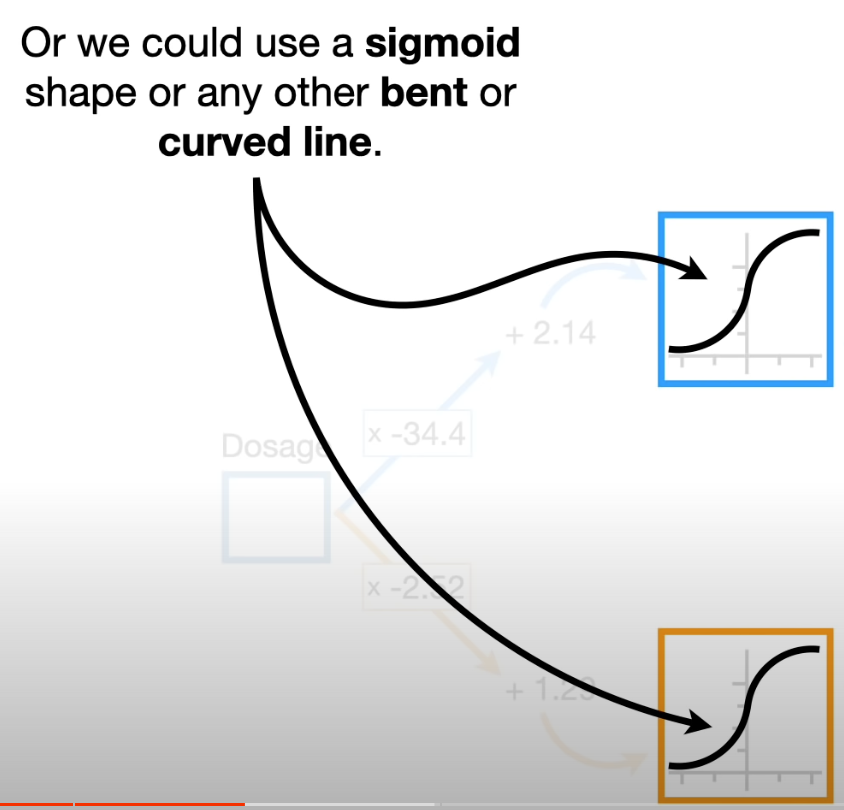
There are many coomon bent or curved linesthat we can choose for a Neural Network.
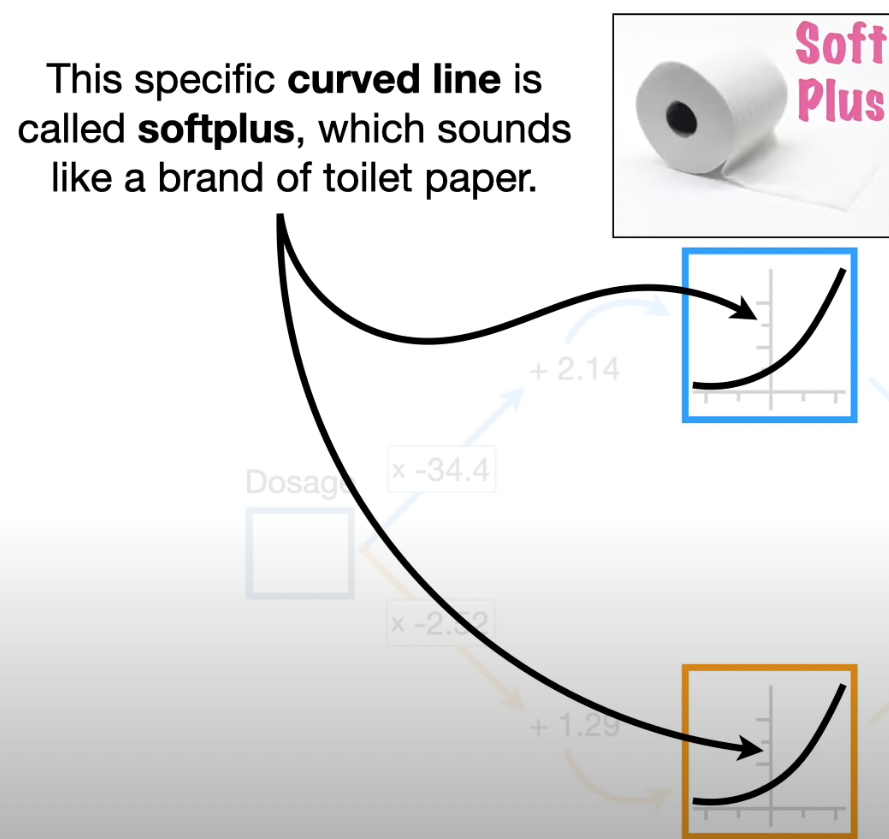
The curves are called Activation Functions
Hidden Layers: nodes between input and output. you have to decide how many layers you want and how many nodes go into each hidden layer
In the connection of nodes, the parameter we add are called biases and the param we multiply
Part2: BackPropagation
- using the Chain Rule to calculate derivatives.
- Plugging the derivatives into Gradient Descent to optimize params.
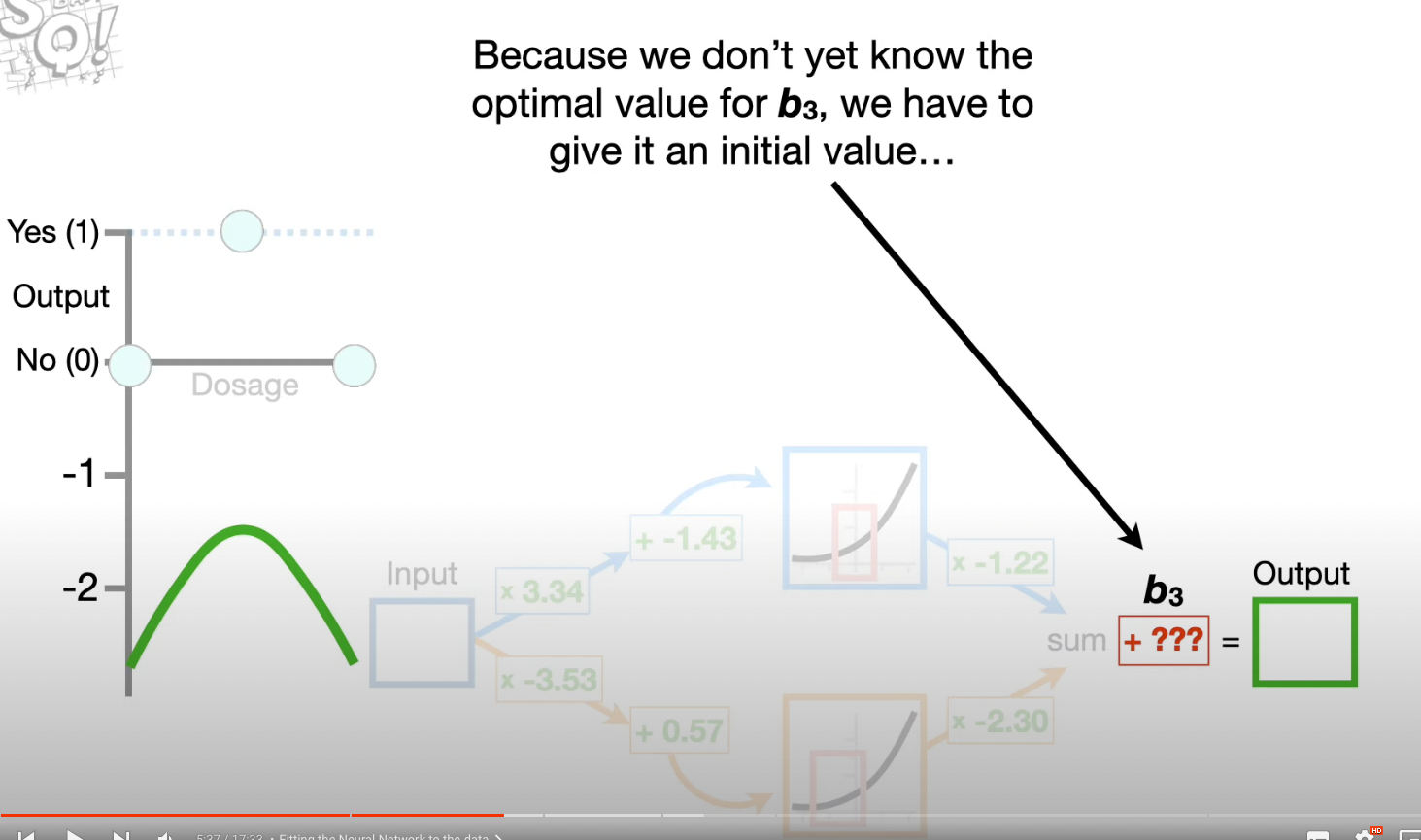
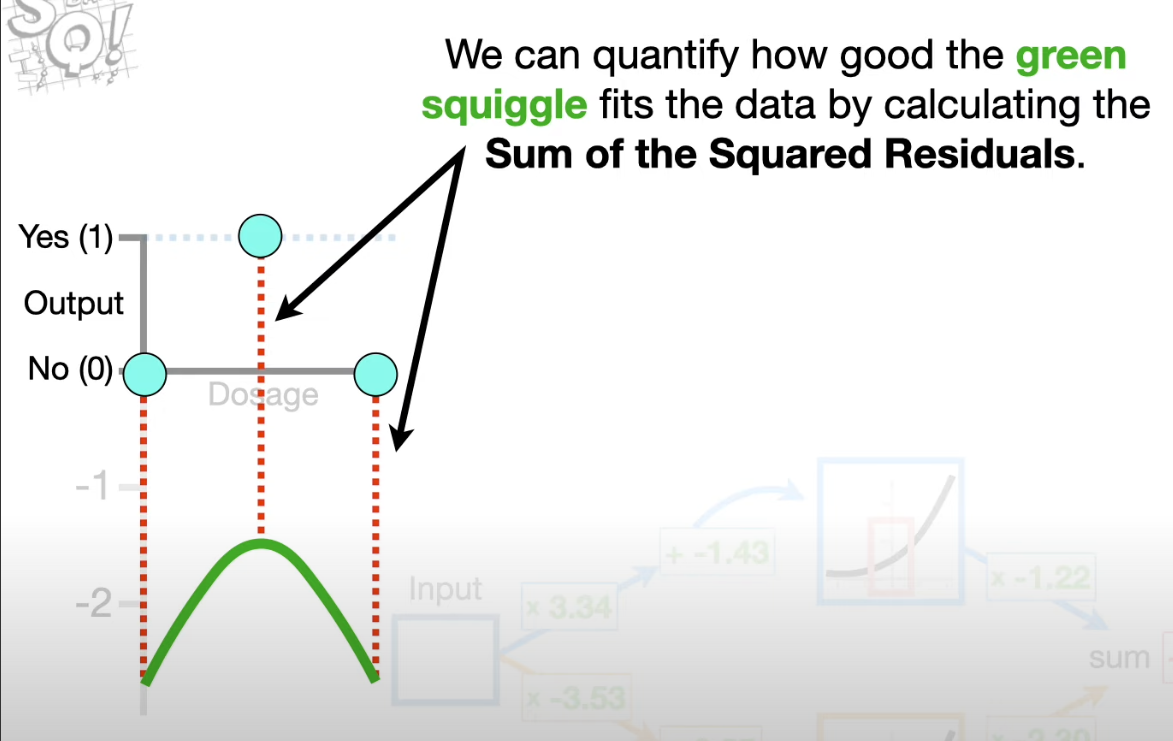
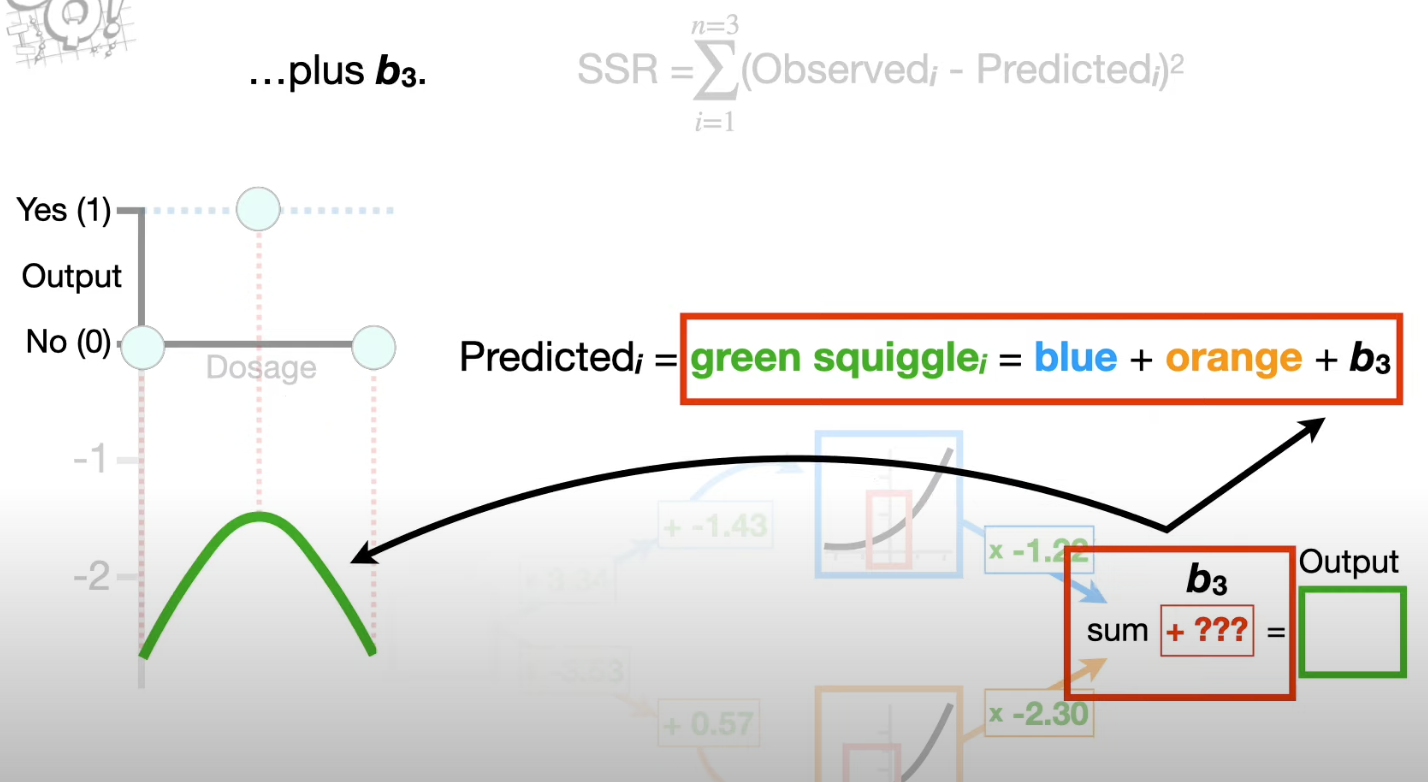
- quantify how well the green squiggle fits the data by calculating SSRs
the process of Gradient Descent
- Then caculate the optimal value for
where we can get the smallest SSR (use Gradient Descent to find this value relatively quickly) 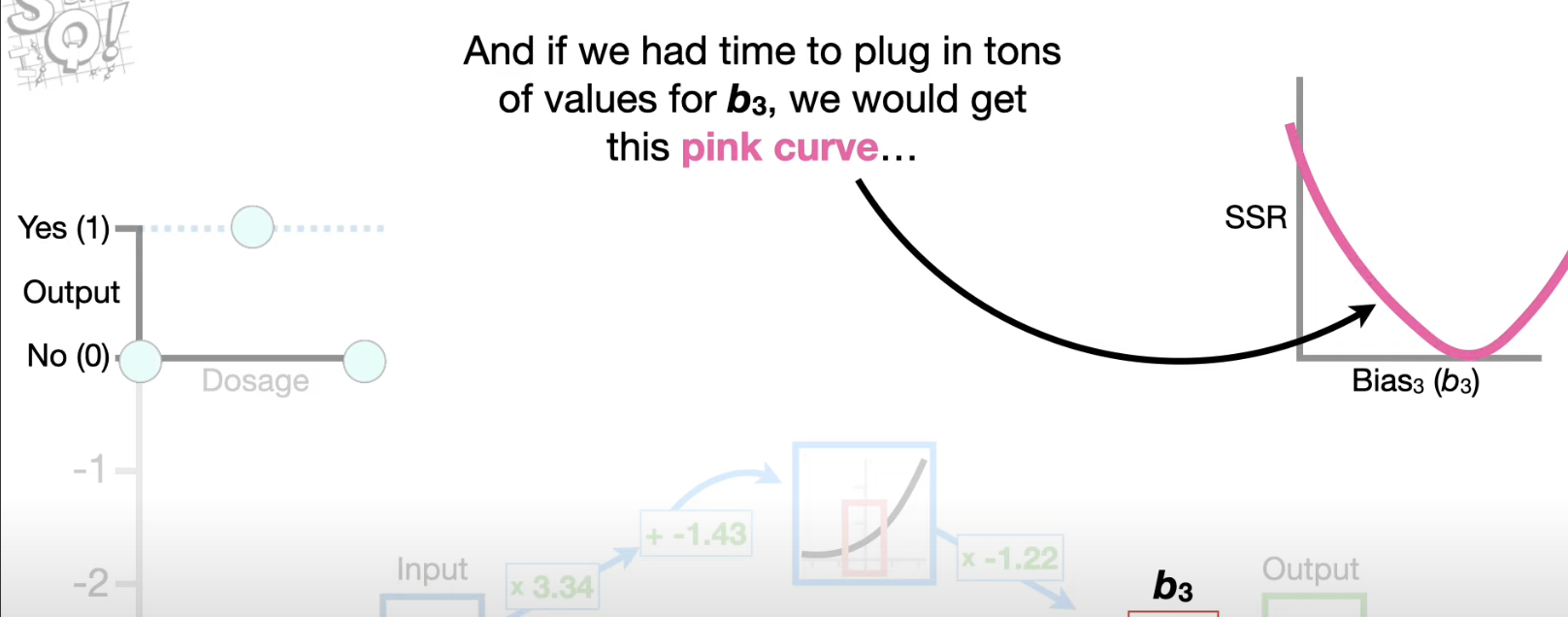

using the step size we can get the new
Details p1
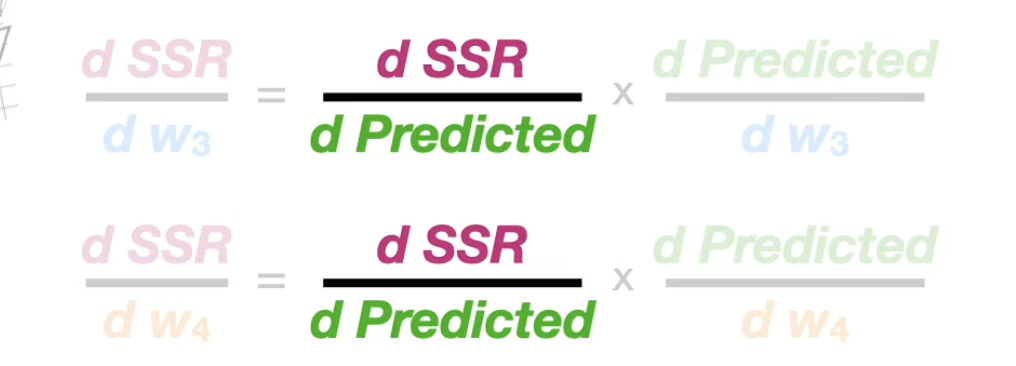
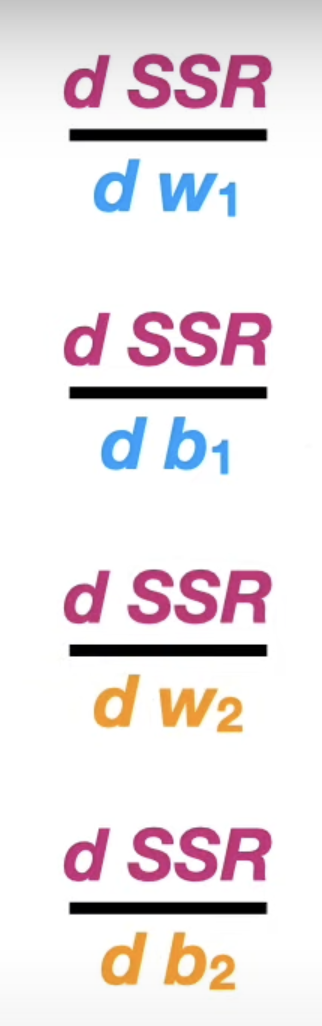
How the Train Rule and Gradient Descent used in optimizing multiple parameters.
Assuming we have
Randomly select 2 values for w3,4 from a Standard Normal Distribution
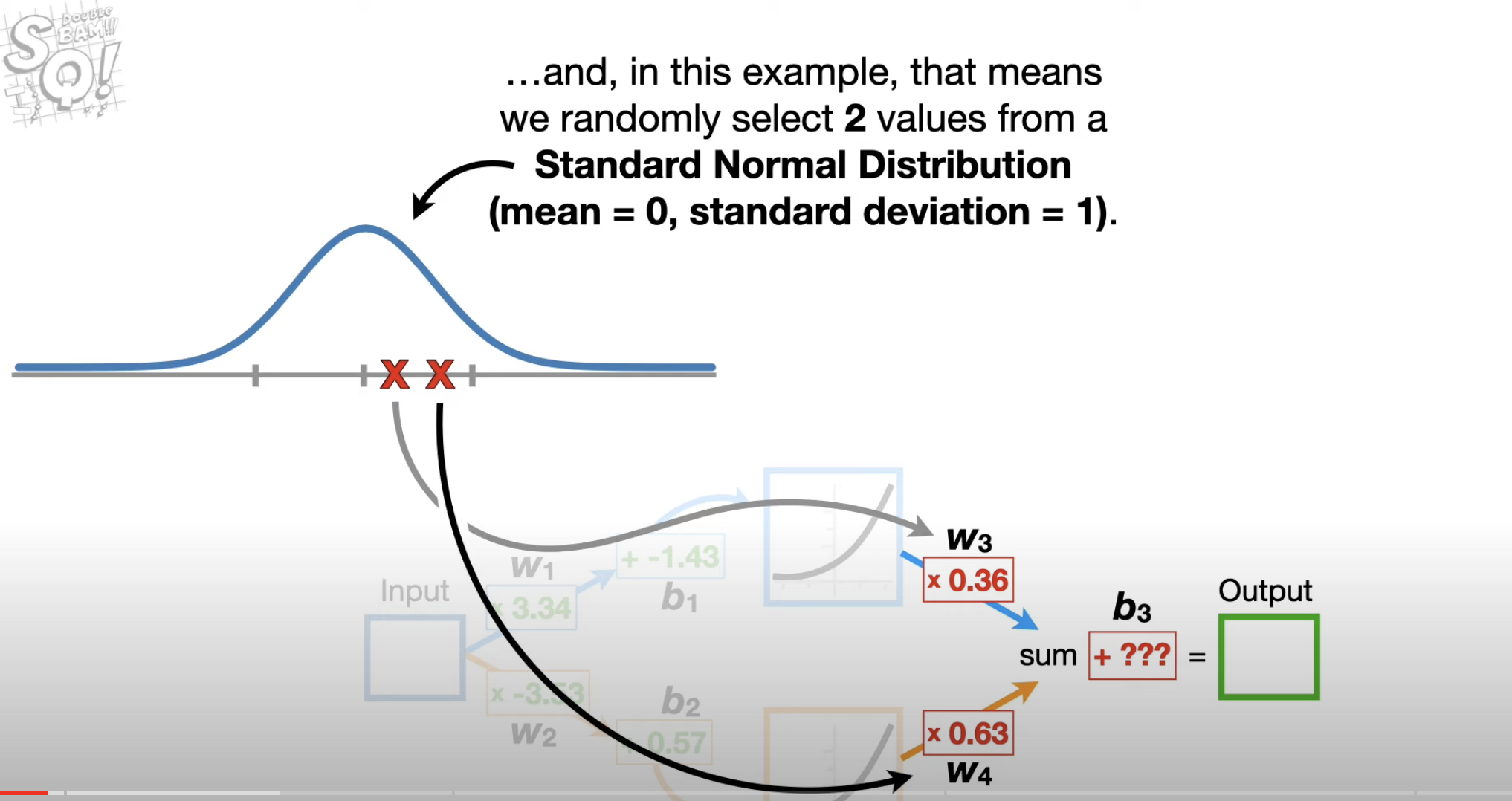
Optimize the
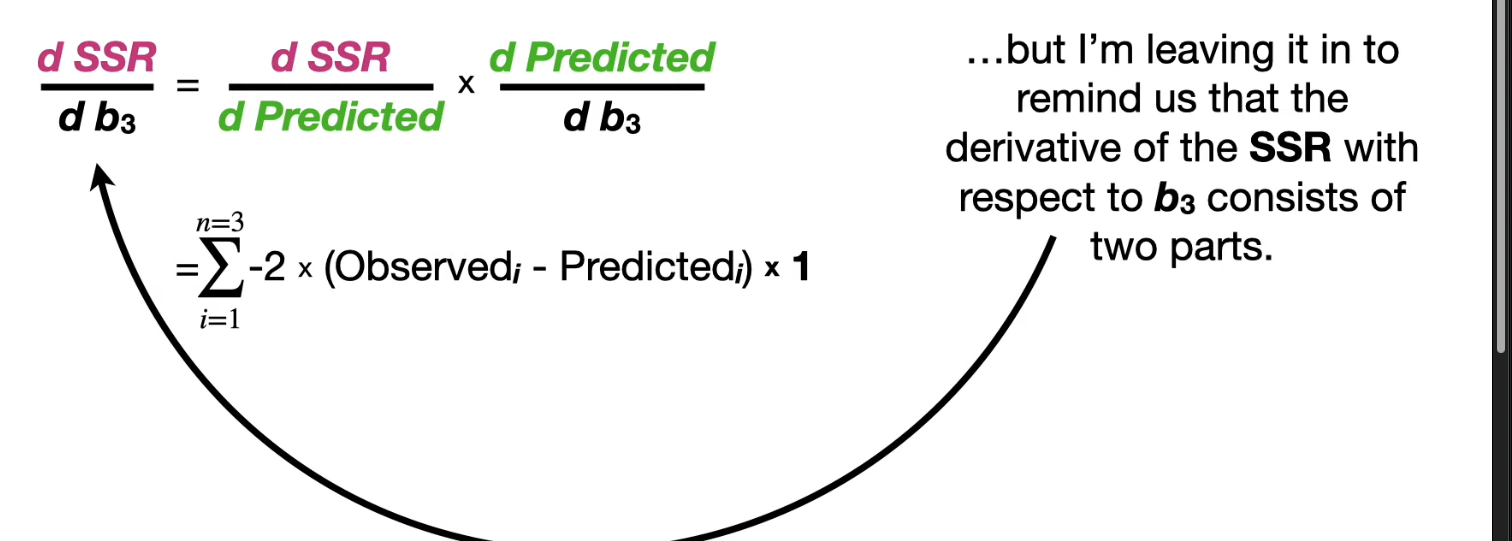
even if are not optimal. The reason why it works is that dSSR/db_3 is not related to w_3,w_4.
calculating the derivatives
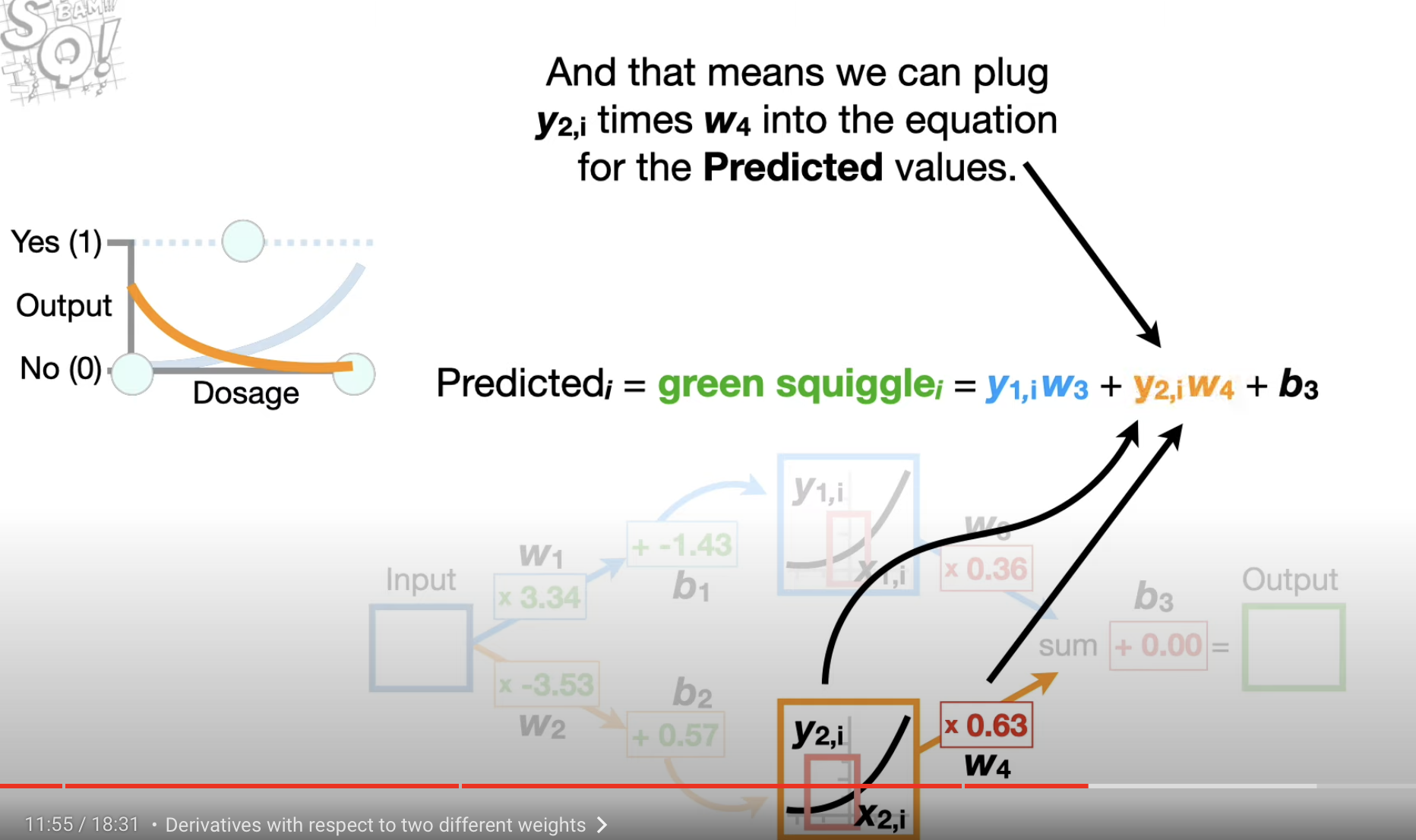
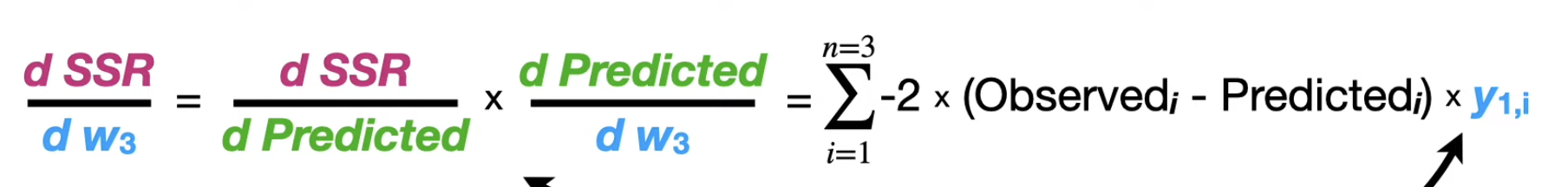
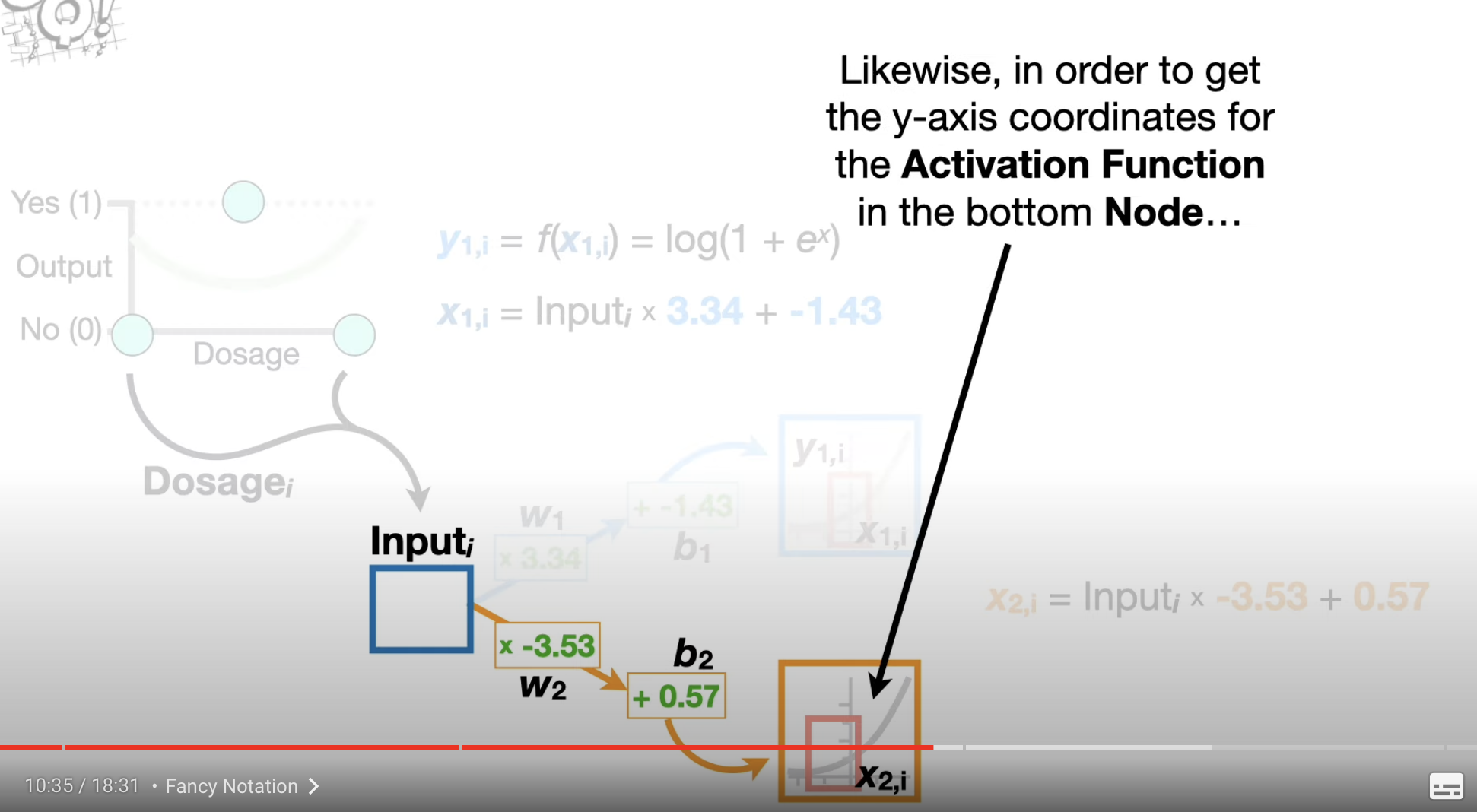
represent the value got by plugging in into the Activation Function . represents the value which we got in the connection of by plugging in th value of
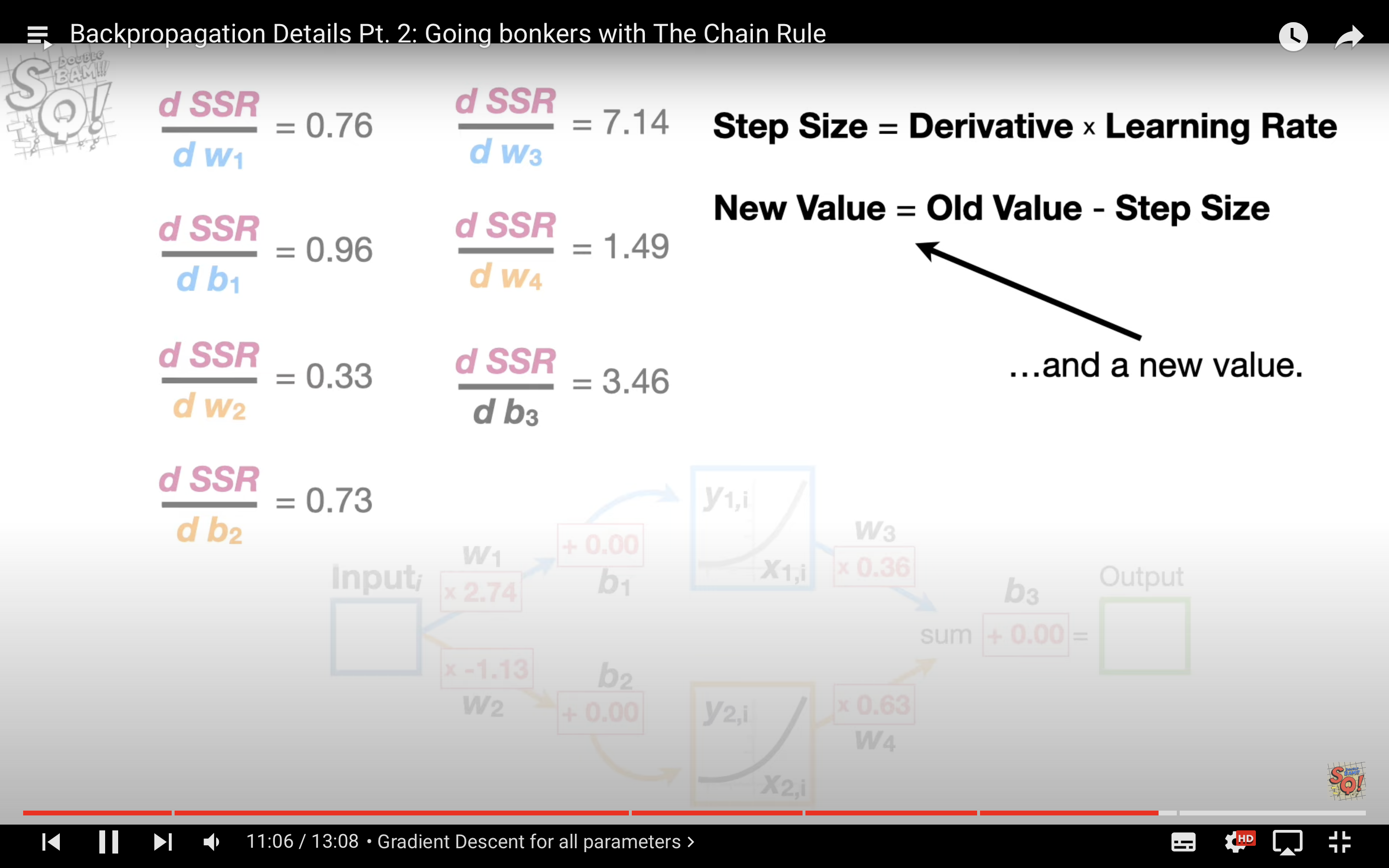
- calculate the Step Size. Stepsize = derivative
learning_rate - new (weight || bias) = old_one - stepsize
Repeat the steps until:
- the performance not improved very much
- reach the step limits
- …or meet other criteria
part2
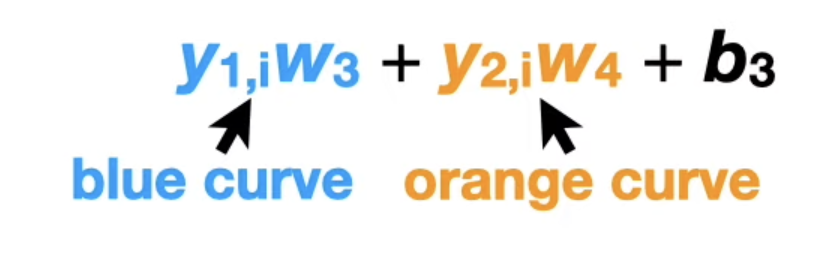


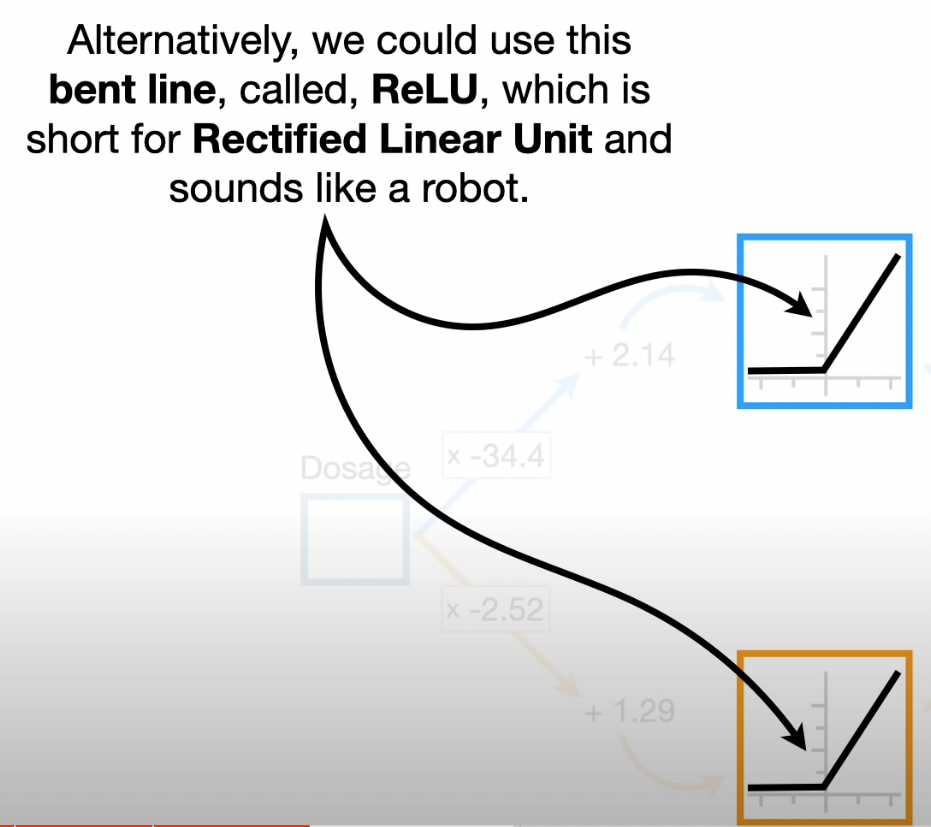
Part3 ReLU

Part4
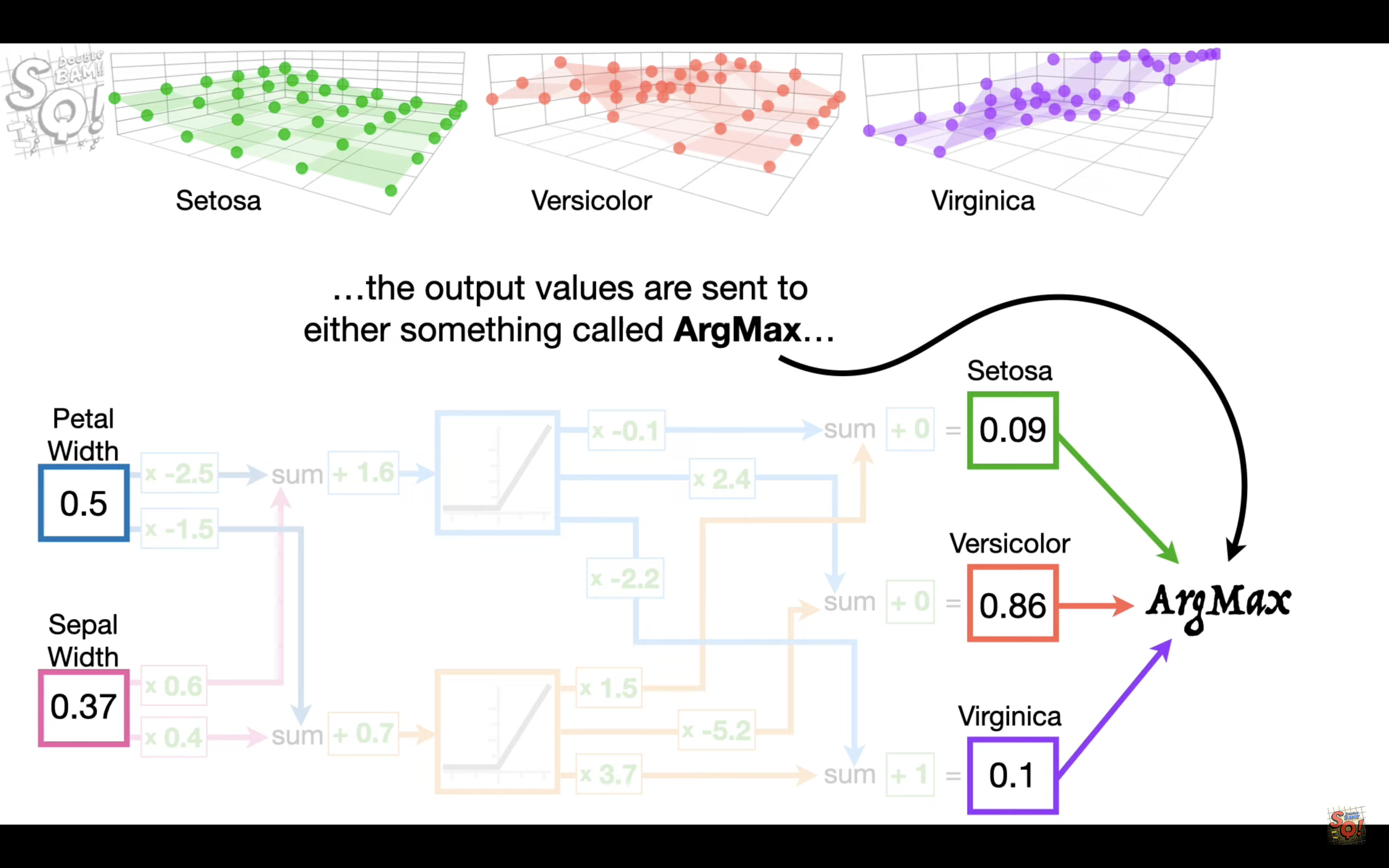
Part5 ArgMax and SoftMax
We can’t use Argmax for BackPropagation
When people want to use ArgMax for output, they often use SoftMax for training.
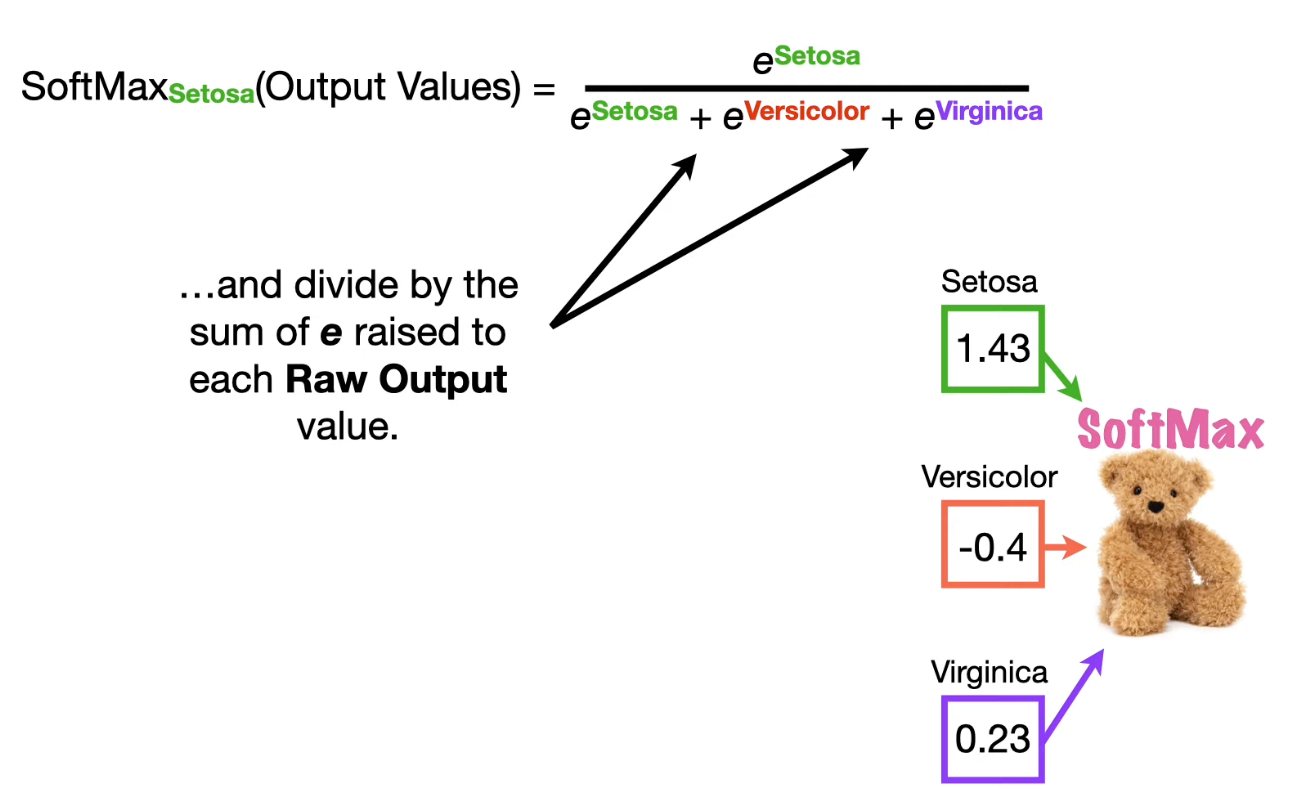
The output values of SoftMax range from 0~1
The value of the SoftMax output can be interpreted as Predicted “probabilities”, to some extent. We cannot put much trust on it because this so-called probability is depend on the weights and biases which may just be initialized to a random value.
SoftMax used in Back Propagation
and….

When we use the SoftMax function, the output becomes the “probability” between 0 and 1.
Cross Entropy, thus, is often used to determine how well the Neural Network fits the data.
Part6 Cross Entropy
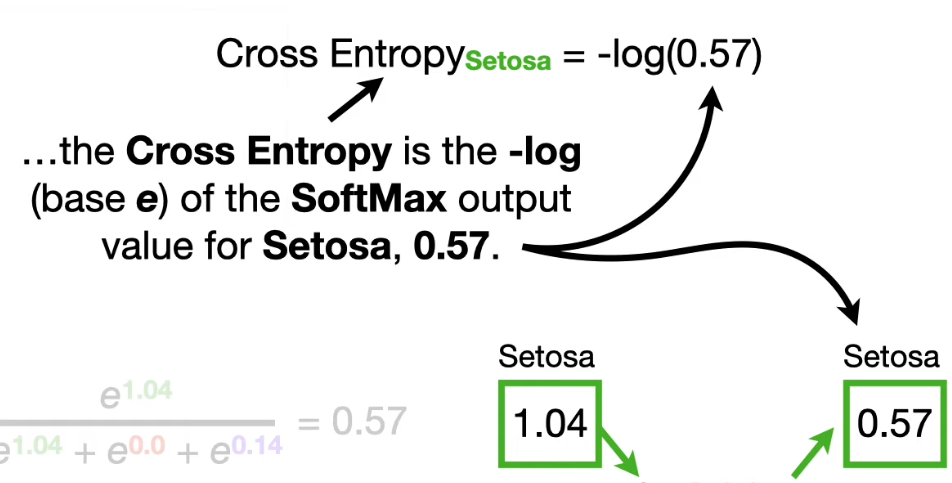


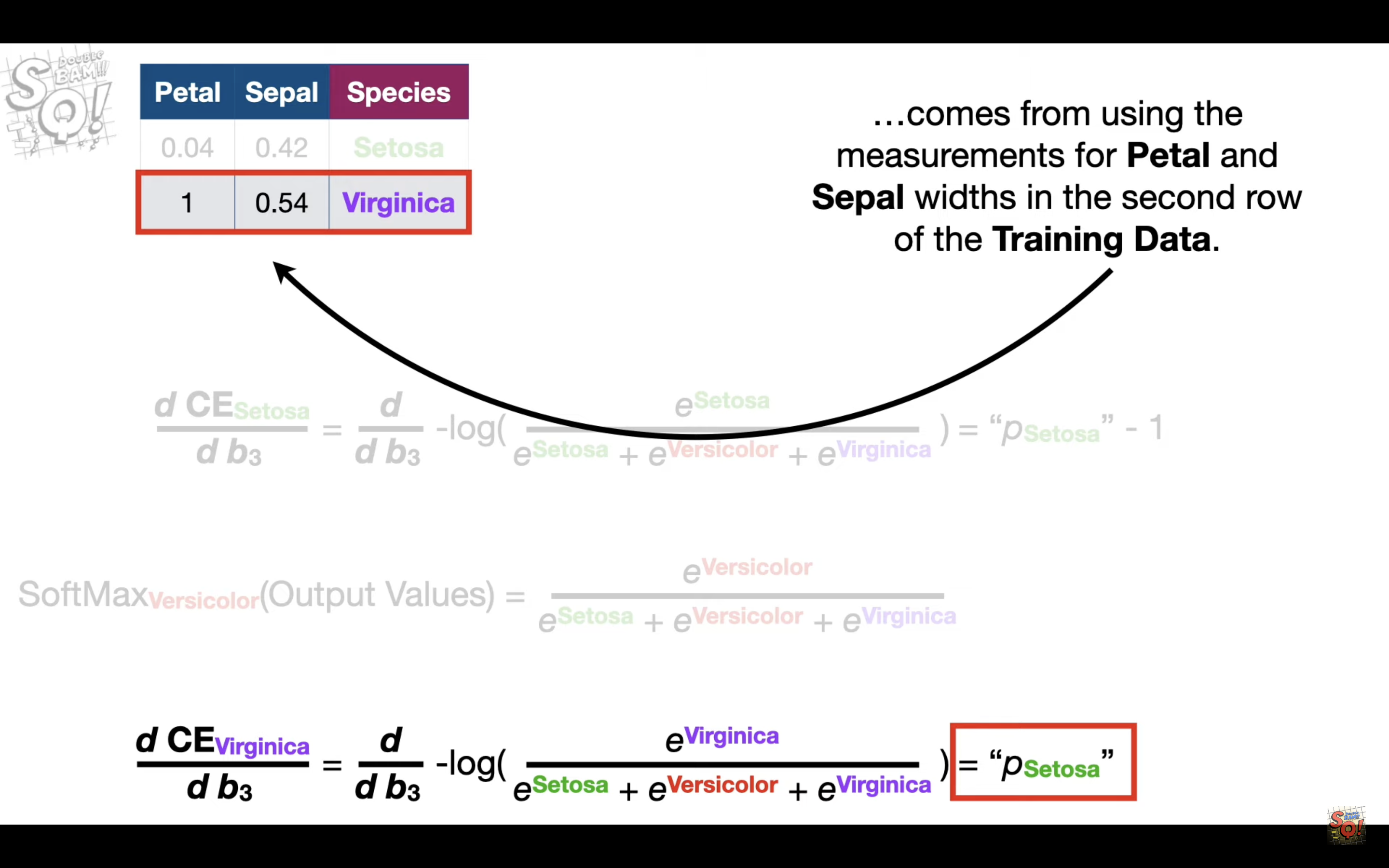
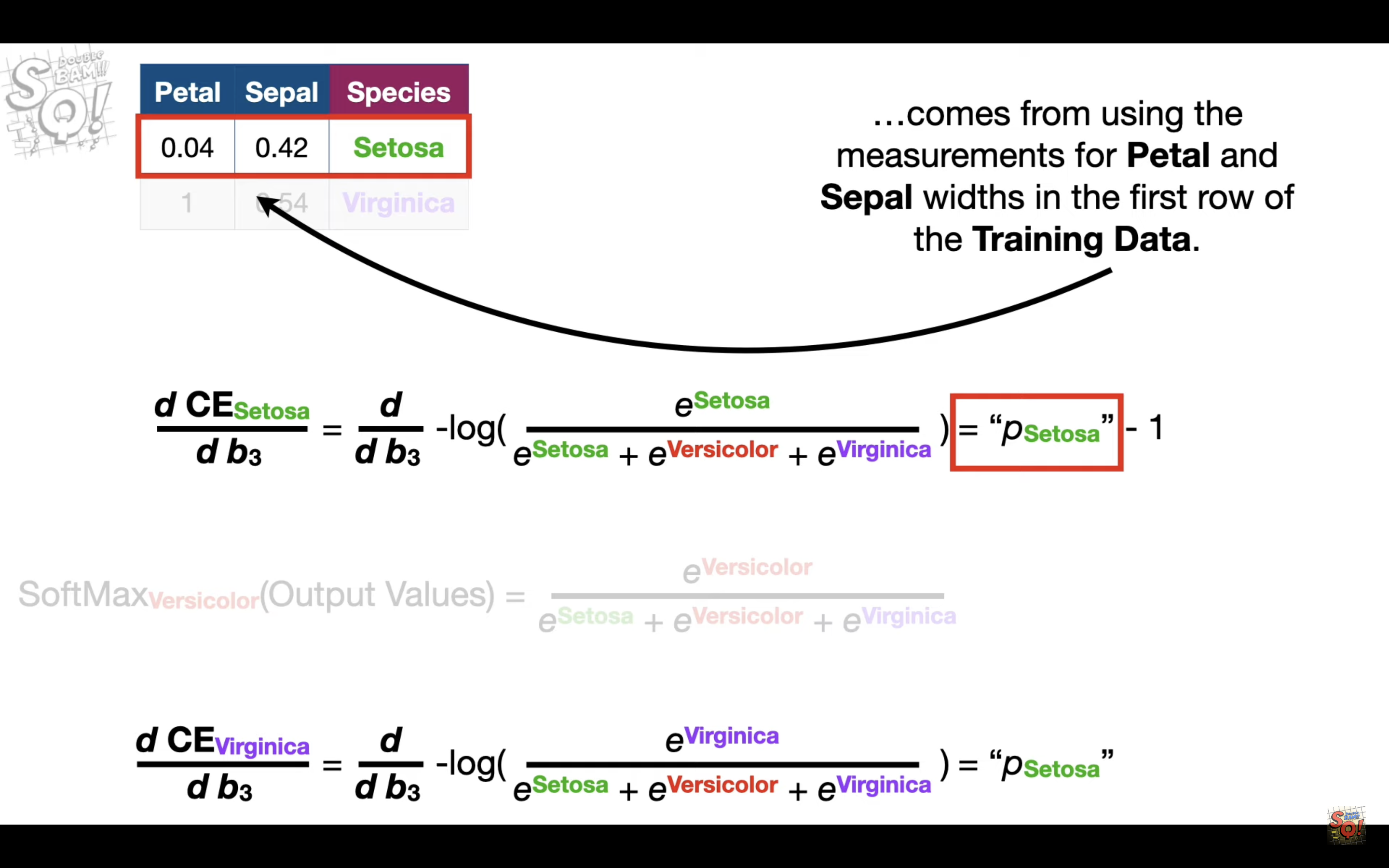
When calculating CrossEntropy_i, only the Observed_i =1, others are 0.
- Total errors are the sum of Cross Entropy
- Residual = 1 - predicted_probability.
Part7: Cross Entropy and Backpropagation

BAM!!
WHY?
The total cross entropy is calculated by…(where n is the number of data points)
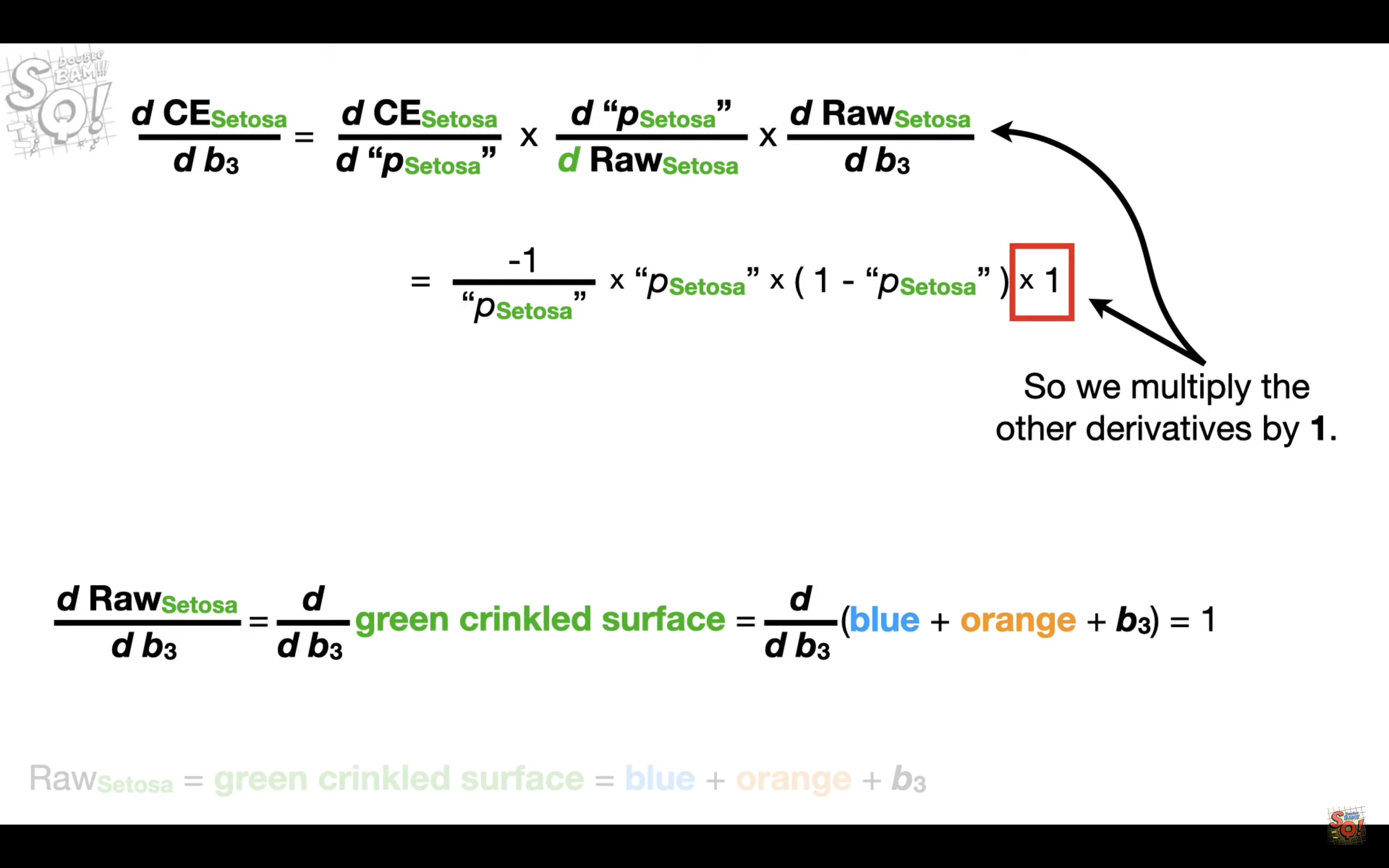
When we want to take the derivatives, in this case, of b_3
For every predicted value, only one component(in this case Setosa) is determined by b_3, so
Part 8: Convolutional Neural Networks
3Things:
- Reduce the number of input nodes
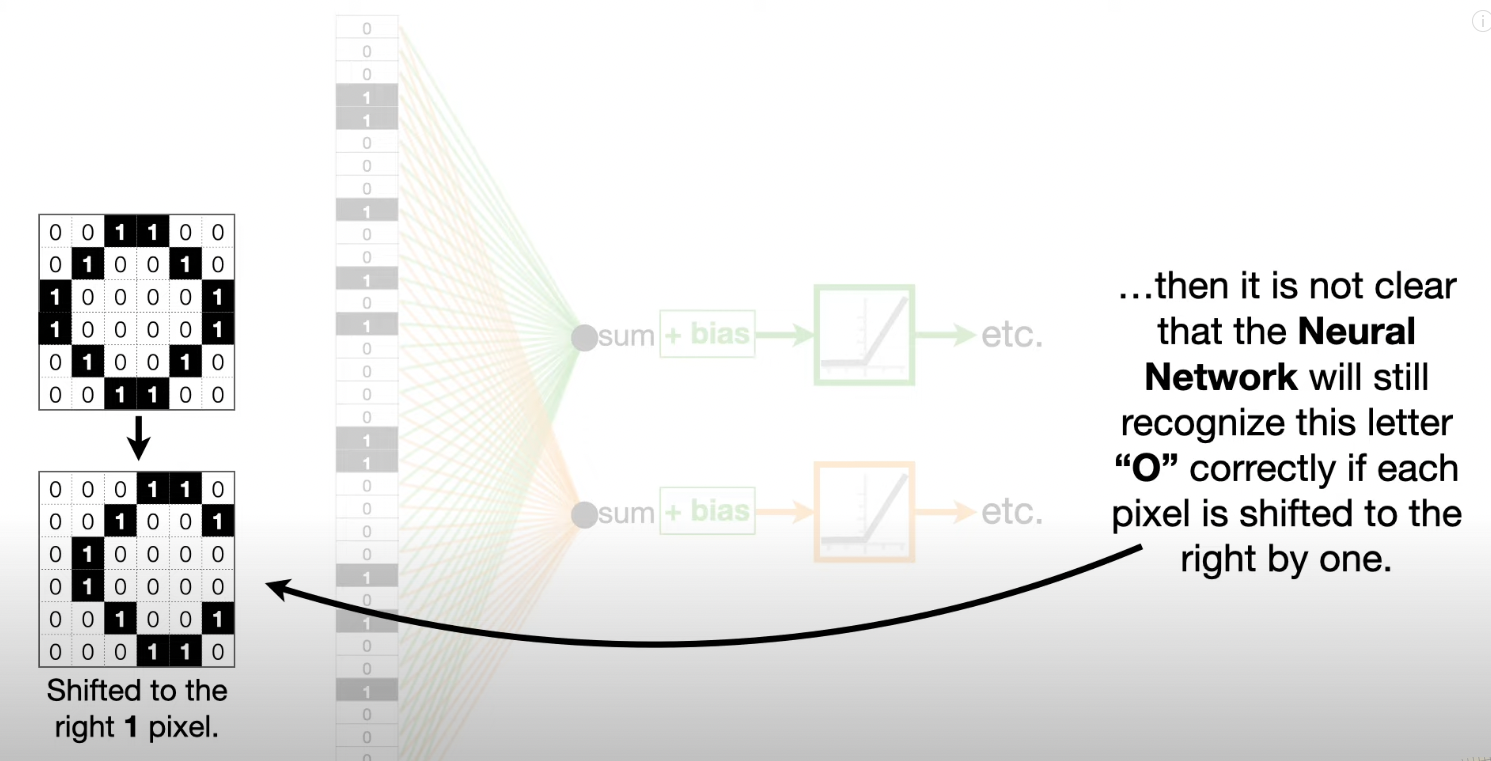
- Tolerate small shifts in where the pixels are in the image.
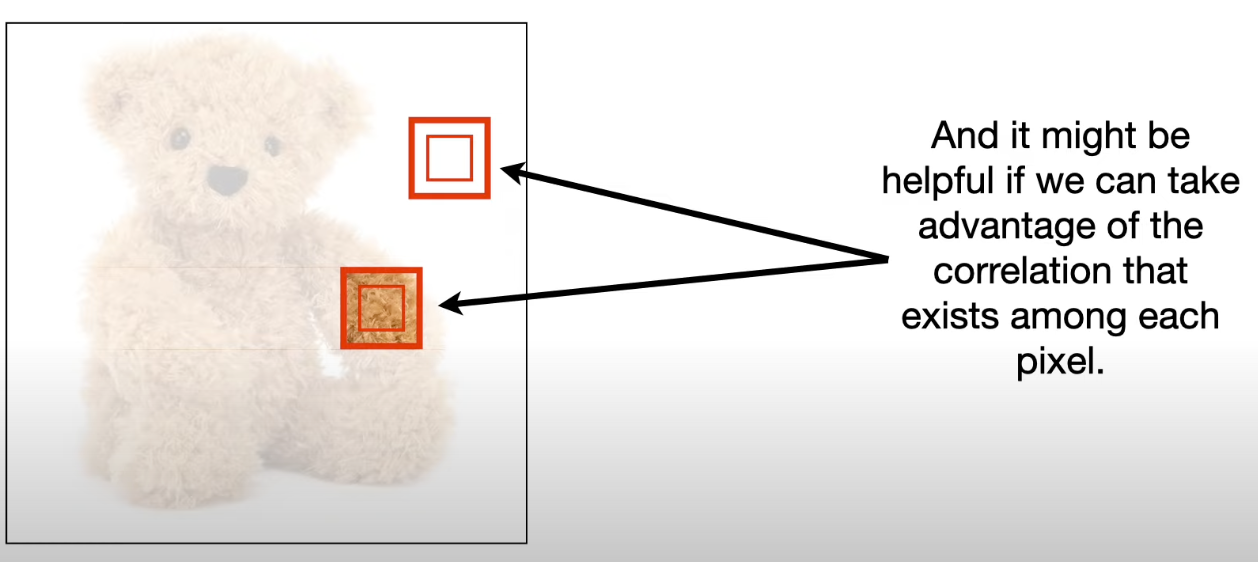
- Take advantage of the correlations that we observe in complex images
Steps:
Take a Filter(aka Kernel). The intensity of each pixel in the filter is determined by Backpropagation
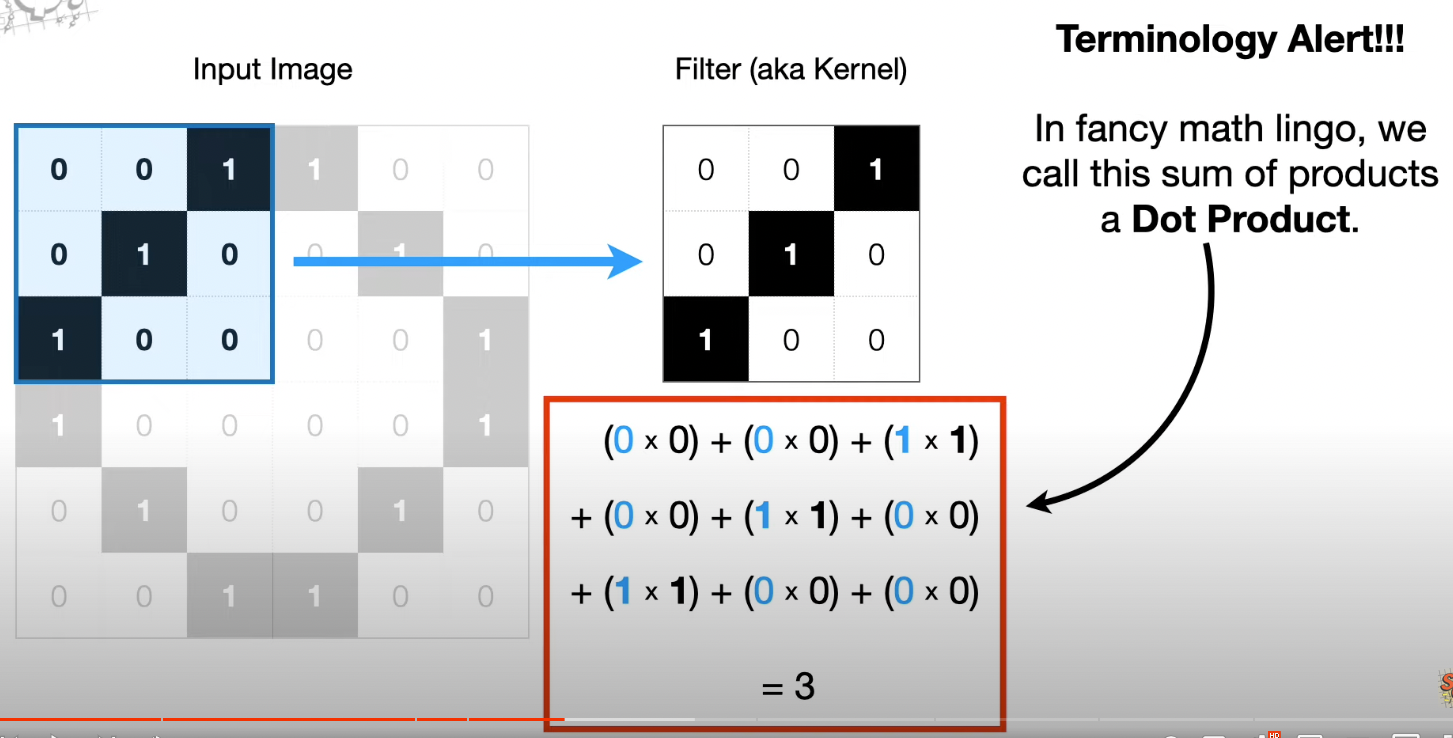
And we can say the Filter is convolved with the input.
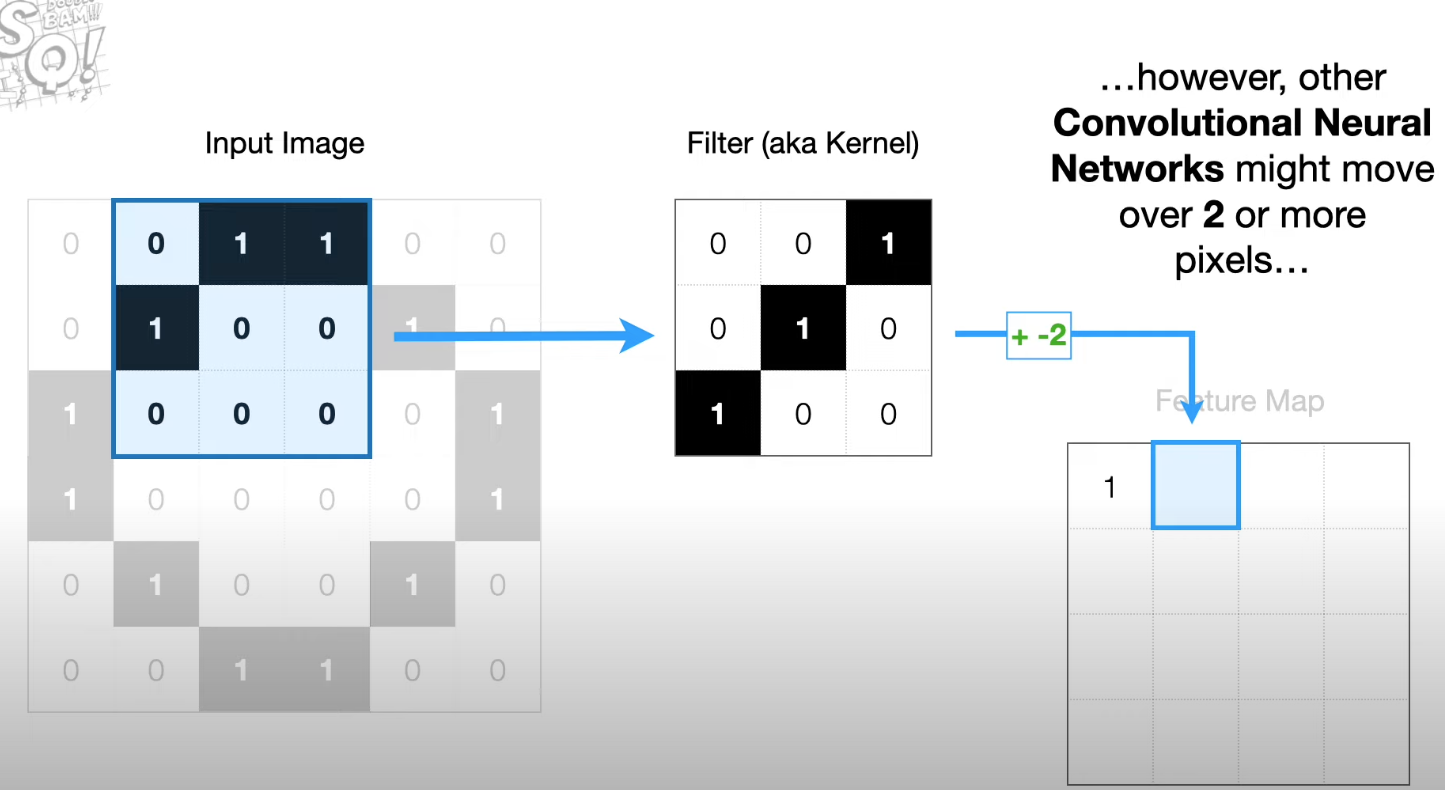
Move over one pixel and we can get a Feature Map
Each cell in the Feature Map corresponds to a group of neighboring pixels.
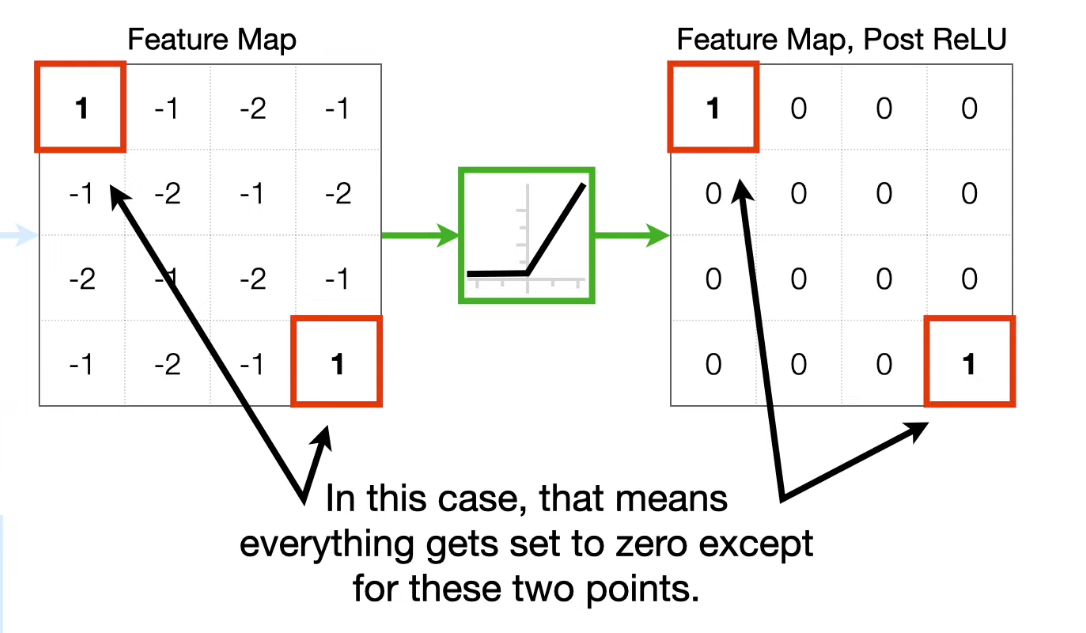
Run the feature map through ReLU function.
We simply select the maximum value ? and this filter usually moves in such a way that it does not overlap itself.
- When we select maximum value in each region, we are applying
Max Pooling - when calculating the average value for each region, this would be called Average or
Mean Pooling
- When we select maximum value in each region, we are applying